Your data is in five systems.
Your report is in a spreadsheet.
That's the problem.
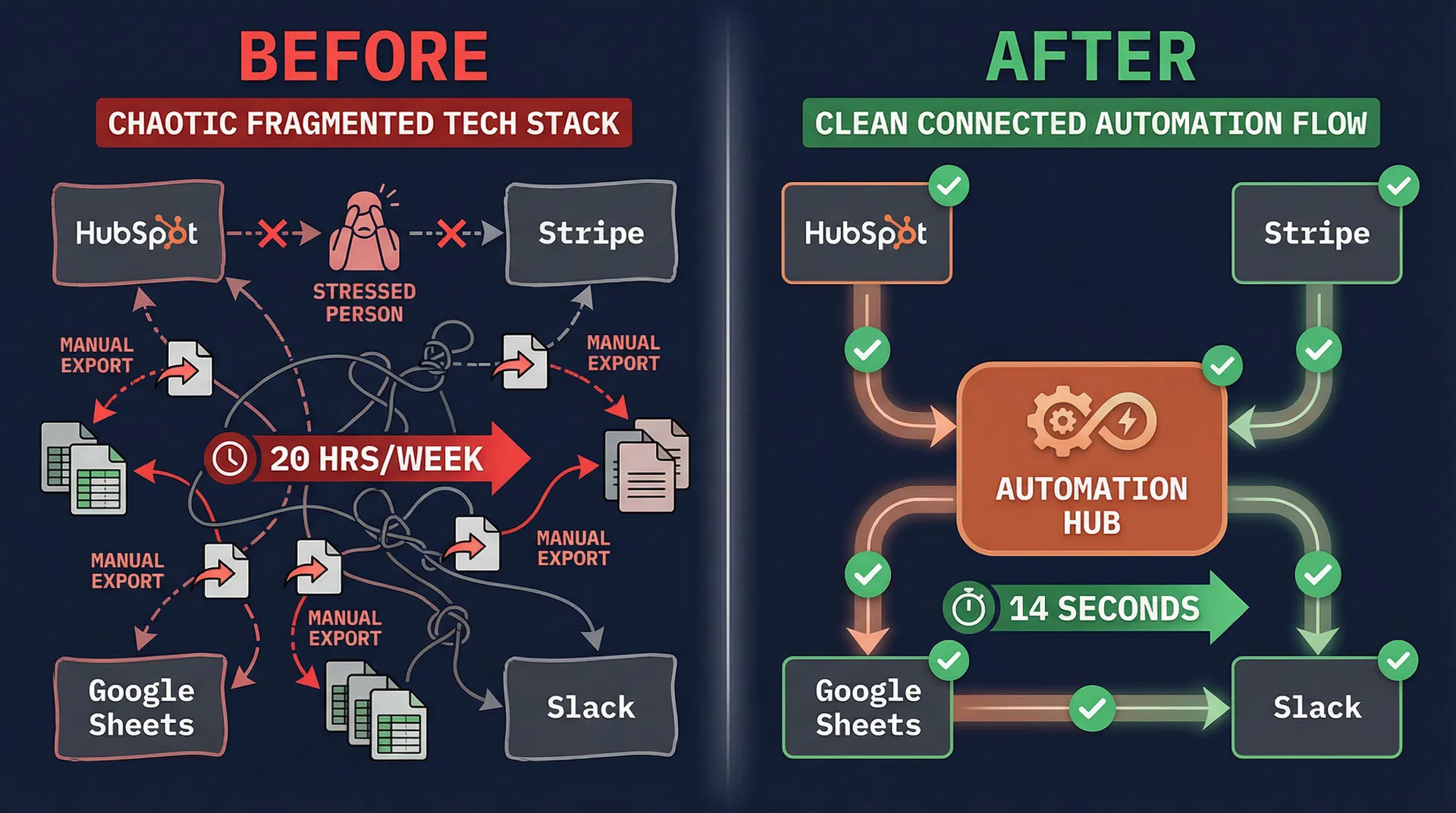
Operations teams across industries spend 8–12 hours every week doing the same thing: exporting CSVs, running VLOOKUPs, reconciling numbers that don't match, and building reports that are already stale by the time leadership reads them.
The problem isn't your team. It's that your systems don't talk to each other, and nobody's built the bridge.
"I would spend an entire day getting the report together — and maybe only an hour actually analyzing it."
Four systems. One consultant.
No platform replacement.
Pipeline Reporting Automation
Scheduled pulls from your CRM, billing, and marketing tools. Data cleaned, metrics calculated, AI narrative written, and delivered to Slack or email before you finish your coffee.
CRM Data Quality & Sync
Bi-directional sync between your CRM, billing, and support tools. Deduplication at the point of entry. Field validation that catches errors before they cascade.
AI Revenue Intelligence
AI-powered narrative analysis that transforms raw pipeline metrics into executive-ready insights with specific deal callouts, risk flags, and recommended next actions.
Revenue Stack Integration
End-to-end integration architecture connecting your CRM, billing, marketing, and support tools. Built on Make.com or n8n — no proprietary platforms, no vendor lock-in.
The numbers behind every engagement.
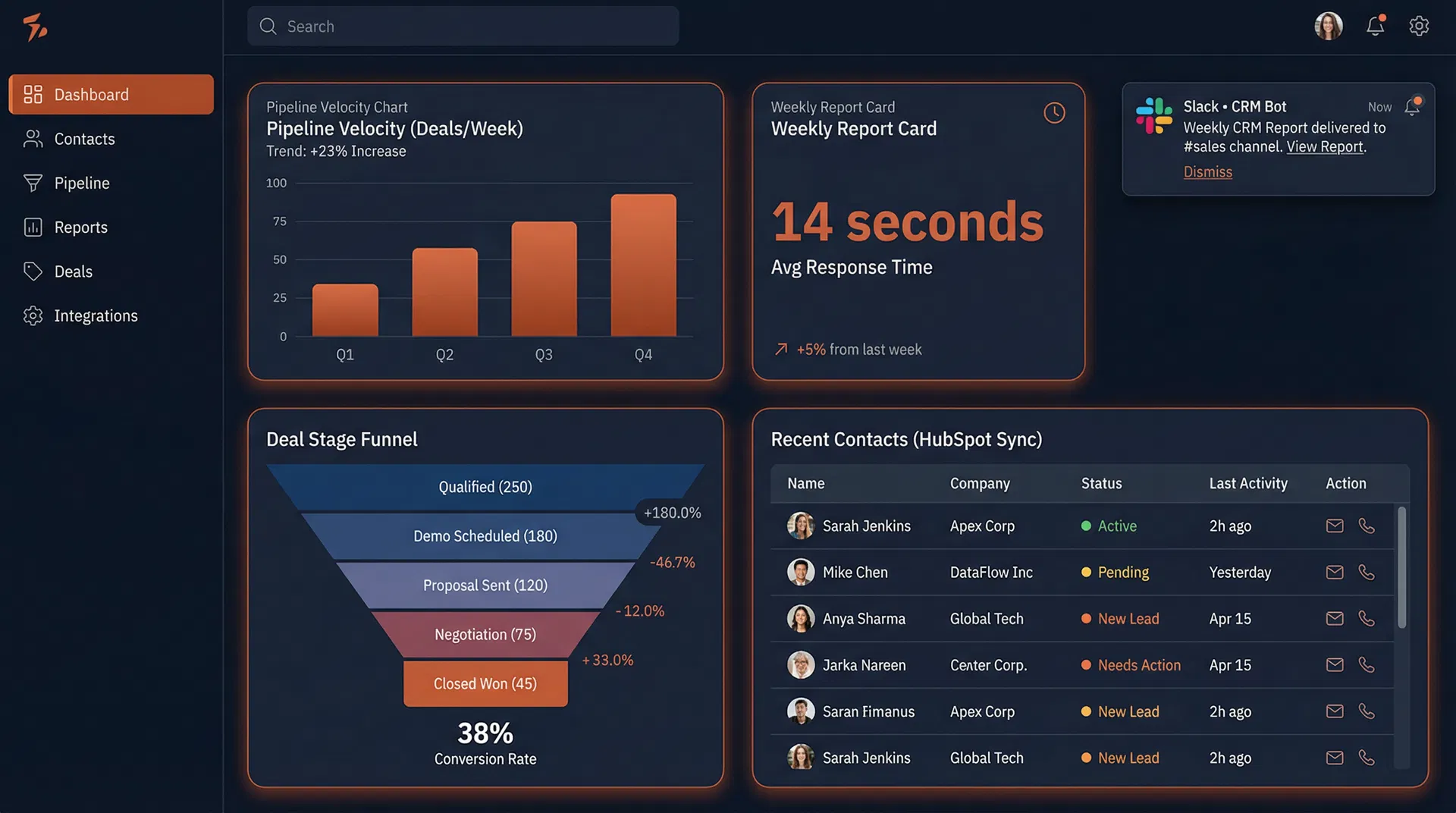
8 source systems consolidated into a single automated Monday morning Slack report. The VP of Sales now reads the executive summary with coffee instead of building it.
Three phases.
No surprises.
Audit
1–2 weeksWe map your current reporting workflow step by step. Every manual touchpoint, every system, every handoff. You get a complete picture of where automation creates the most value — and a clear implementation roadmap.
Build
2–6 weeksWe build the automation pipeline on your existing systems. HubSpot → Stripe → Google Sheets → Slack — connected, tested, and documented. Your team can monitor and modify everything we build. No vendor lock-in.
Optimize
OngoingAfter the first 30 days, we review performance data with you. We identify what's working, what needs tuning, and what to automate next. Most clients find 2–3 additional high-value opportunities in the first review.
Security proof, not just security language.
Our data protection posture is built around documented operating steps, not generic assurances. When we touch CRM infrastructure, routing logic, reporting layers, attribution systems, or supporting datasets, the work follows a repeatable model for access requests, environment setup, tool disclosure, incident handling, and clean closeout that internal stakeholders can actually review.
Least-privilege system access
We request only the systems and permissions required for the reporting, routing, attribution, or CRM work in scope. Read-only access is the default, and any elevated access must be explicitly approved.
No off-platform data sprawl
Client revenue data stays inside the approved environment whenever possible. We do not move pipeline, contact, or performance data into personal storage, side spreadsheets, or unapproved tools just to speed up implementation.
Named-operator accountability
Access is controlled, documented, and tied to the specific operator performing the work. That means clearer audit trails, cleaner handoffs, and fewer unknowns when stakeholders review who touched the system.
We do not treat data access as informal admin work. If we are inside your CRM, warehouse, dashboards, automation tooling, or supporting datasets, we use written authorization, named-user access, MFA-preferred authentication, documented scope boundaries, and a defined revocation and destruction process.
Institution- or client-provisioned credentials, with SSO and MFA preferred wherever available.
Encrypted connections, role-based access, and environment-specific secrets management for pipelines and reporting layers.
Documented revocation and data-destruction steps at the end of each engagement or project phase.
No client data submitted to third-party AI tools unless a specific use case is approved in writing first.
Share a concise security summary with IT, procurement, or internal stakeholders before kickoff.
We request access by exact system name, required data elements, access level, technical method, and duration so internal IT teams are never left guessing what is needed or why.
When data work is in scope, repositories, staging databases, ETL orchestration, secrets storage, and dashboards are designed to live inside the client environment rather than being recreated in side systems for convenience.
Each phase closes with documented access revocation, repository handoff, and a written data destruction confirmation so the operating trail is clear after the work is complete.
Access inventory before access is granted
Every system request is documented with the exact access level, data elements, duration, and preferred connection method before any work begins.
Why it matters: clients can review and narrow scope before credentials are issued.
Tool disclosure and AI-use decisions in writing
We disclose which platforms directly process client data, which only touch supporting material, and when AI tools are prohibited or separately authorized.
Why it matters: stakeholders see the stack, the exposure path, and the approval model up front.
Named closeout artifacts at phase end
Access revocation confirmations, repository handoff, and a data destruction letter are treated as deliverables rather than informal cleanup tasks.
Why it matters: IT and procurement teams have concrete evidence that the engagement closed cleanly.
Procurement-ready security responses
The process is built to support HECVAT submissions, vendor registration, incident-response follow-up, and internal review questions without improvising security language midstream.
Why it matters: security review feels like a prepared workflow, not a scramble.
Security controls are adapted to the client environment, data sensitivity, and approved tool stack. Where an engagement involves stricter governance requirements, we can align to institution-specific access reviews, HECVAT submission requirements, documented incident reporting paths, retention rules, and procurement checkpoints before implementation work begins.
How is access controlled during a client engagement?
We scope access to the smallest set of systems and permissions needed for delivery, document the request by system and data element, and default to read-only unless a higher level is explicitly justified and approved before implementation work begins.
Do you move client data into external tools or personal files?
Our default operating model is to work inside approved client environments and avoid unnecessary exports. We do not move data into personal storage, side spreadsheets, or unapproved third-party tools for convenience.
What happens when the project ends?
We use a documented closeout process that covers access revocation, handoff notes, and confirmation of any required data-destruction or environment cleanup steps tied to the project scope.
Can your process support IT or procurement review?
Yes. The operating model is built to support tool disclosure, vendor registration, HECVAT-style questionnaires, access-boundary review, retention expectations, and incident-response follow-up before delivery work starts.
What you're actually comparing.
The questions we get
on every call.
We've pulled the data.
Fixed the broken Zaps.
Built the bridge.
We're a data engineering and workflow automation team. We've spent years building systems that connect fragmented tools, clean messy data, and eliminate the manual work that slows operations teams down — work that a well-built automation can do in seconds.
We started this practice because we got tired of watching smart people burn out on spreadsheet maintenance. The tools to fix it exist — n8n, Claude AI, and modern APIs can automate almost any workflow. Most teams just don't have the engineering depth to connect them.
We work with a focused set of clients at a time. That's intentional. When we're on your project, we're actually on your project — not handing it off to people who've never seen your stack.

Data engineer and AI automation specialist. Builds n8n workflows, Claude Code integrations, and data pipelines that connect your tools and eliminate manual work.
Free Stack Review.
No pitch. Just the math.
45 minutes. We map your current reporting workflow, identify the top 3 automation opportunities, and give you a rough ROI estimate. You leave with a clear picture of what's possible — whether or not we work together.